
Machine learning in price and profit optimization
Machine learning refers to the study of computer algorithms that improve automatically through experience. It is seen as a branch of artificial intelligence and it focuses on automating analytical model building. It is based on the idea that systems are able to learn from data, identify patterns and make decisions with minimal human interaction. As our profit optimization module is based on machine learning and artificial intelligence, we took the time to write down a comprehensive article on this topic.
Why is Machine learning so useful in pricing
Even though humans are capable of incredible feats, we have our limitations. We invented computers, developed them and will continue to develop them, at least to the point of singularity, at the moment there are already some things computers can do better than humans.
Computers are able to process a vast amount of data that would take humans a really long time and could even be impossible for humans to process manually. Where humans might be able to provide models on a category or SKU level for key products by processing them in Excel, a computer can do the same for all products, regardless of the amount. On a similar note, computers don’t have the processing limitations that leave only key products with optimized prices since computers can process entire inventories and reprice all SKUs globally.
One thing that surfaced as a fear when thinking about whether computers would take over human’s jobs was the fact that computers don’t really need to rest. They can work 24/7/365 whereas most humans work 9 to 5 and only 5 days a week, from Monday to Friday.
With the COVID-19 pandemic we have seen that changes in the market can be almost instantaneous. The demand for a specific product can explode in a matter of hours and the people benefiting from these changes are the ones who are awake and working when the changes occur. A computer is able to process the information in almost real time, making it possible to react to changes on the market rapidly. A human would need more time and effort to do this and sometimes still be too slow to take advantage of the situation.
As mentioned above, one of the key functions of machine learning algorithms is to learn patterns from data. In this situation, machines often spot patterns that humans miss or simply wouldn’t take into account. By using machine learning there is no need to program logic for the patterns and the constant integration makes detection of new patterns or changes in demand extremely fast.
If you look at the challenges of pricing and the benefits of machine learning it should come as no surprise that the reason we talk so much about it, is because by using machine learning assisted pricing YOU will become a better pricing professional. It is not about letting a computer take your job, it’s about using computers to your advantage by letting a computer do the work that computers are good at. Becoming a good pricing professional is largely based on having a good understanding of the market and insights into what is changing.
As we saw earlier, computers are good at processing large amounts of data and that is
exactly what a pricing professional needs when making pricing decisions. You need real time data about the market and a quick way to spot trends and changes that you should react to. Very few people enjoy making uninformed decisions and when it comes to pricing, there are many factors to take into consideration.
Here are some of the frequent questions that machine learning can help you answer:
• How were the sales impacted by an increase or decrease in price?
• How does the price increase/decrease in a product like lemonades affect related products like
juices (i.e. possible market cannibalization)?
• When a sale occurs, what is the likelihood of a customer also buying something else in the following days, weeks or months?
• Are promotional campaigns effective in activating customers?
By using computerized methods for tracking and modelling trends you can be sure that your decisions are backed by data, not by hunches and blind luck. Predictive models allow pricing professionals to test different scenarios and determine the best price for each product or service. You are able to evaluate the impact of sales promotions, estimate the right price if you need to take into account factors like best before date.
Predictive models can also be used for predicting price and demand for products that have never been sold before e.g. introduction to market situations. The more data you have and the more you are able to understand the consumers reactions to changes, the better you will be as a pricing professional.
When it comes to why you would use machine learning instead of traditional rule based learning it all boils down to the amount of possibilities that machine learning offers.
You are able to develop much more complex strategies than with rule based pricing strategies. As long as you define simple goals and limits your machine learning model will be able to adapt easily and live within the parameters you have set. Machine learning in pricing also makes adapting to crisis situations like the COVID-19 pandemic faster, increasing your business’s survival rate. The models can be adjusted to consider the near past more important than the older past and thus focusing more on recent times when making predictions for the future.
This blogpost is based on our e-book "AI in pricing"
Neural networks
Artificial neural networks (ANNs) are a set of algorithms that learn to perform tasks without being coded with task-specific rules.
A biological brain like the human brain is made up of neural networks. Neural networks consist of neurons; a single unit that is able to perform some very basic functions or actions. Computers are able to “simulate” functionality of biological neural networks with artificial neural networks that are in principle quite similar to the biological neural networks in our brains.
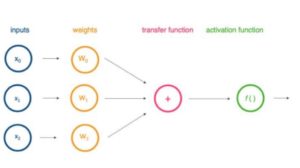
The neural networks used in artificial intelligence are inspired by biological neural networks. These artificial neural networks only tend to be simpler than their biological counterparts. As mentioned earlier, neurons are able to perform simple tasks when they are alone, but when they are combined with other neurons, they form a network and the tasks the network is able to perform suddenly becomes increasingly complex leading to a highly advanced and large amount of processing capacity. In a neural network, both in the biological and in the artificial, the task of the neuron is to receive and transmit signals and that is what they do, enabling a vast network to emerge.
“In neural networks, each neuron processes data independently from each other, making them able to process more info.”
In artificial intelligence, deep learning is a concept where several layers of simple processing units (neurons) are connected into a network where the input is passed through each of them one after another. When low-level data is processed within these layers, neural networks will adapt and learn and so called “intelligence” will emerge without e.g. a human programming explicit instructions.
One of the advantages of neural networks compared to traditional programming is that instead of traditionally programming in explicit instructions for a program, where a central processing unit (CPU) executes and processes these one after another focusing on one thing at a time, neural networks are able to process lots of information simultaneously. In neural networks, each neuron processes data independently from each other, making them able to process more info . You can sort of think of this as the difference between parallel and series circuits in electrical devices. One (series) runs after another whereas the other (parallel) runs simultaneously.
Like discussed above, all neural networks have a layer-like structure. This means that there is an input layer that gets the initial data and an output layer that produces the output of the whole network. In between these layers there are usually one or more hidden layers that take the output of one layer as its input and output that to the following layer as an input. To recap, all neurons in a layer get their input from a previous layer and output that to the neurons in the following layer.
Each neuron in the neural network has a set of adaptive parameters called weights. These weights are similar to linear and logistic regression and act as multipliers on the inputs to get a linear combination. In this situation using the word “weight” is really quite descriptive as it gives you an idea of what the function does: it places weights on different inputs and thus steers the process in a certain direction.
There are lots of different sizes of artificial neural networks from small to large to very large. Depending on the application, the largest ones can contain hundreds, thousands, millions or even billions of weights.
Let’s take a quick practical example and return to our hypothetical coffee shop presented in our Market cannibalization blog post. If the amount of cupcakes sold depends on two factors; the amount of frosting on the cupcake and price of the cake, you would need to study how the amount of frosting affects the purchase decision and the same goes for the price and after that you would be able to put a weight on both factors. It might be that the amount of frosting modifies the purchase decision threshold with double the intensity of modifying the price, but this might all change when we reach a certain price point. This is just a rough example but illustrates quite well how complex the data the neural networks need to be able to process as the inputs and outputs change when travelling in the layers.
After taking the weight into account and computing to a linear combination the neuron performs an activation function, which defines the final output of a neural network layer.
There are a few different types of activation functions, such as the following:
The neuron does nothing to the value of the linear combination and passes it to the next layer, basically being exactly the same as a linear function.
Output 1 if above some value or threshold, else output 0.
A “soft” version of a step function.
A.k.a (ReLU) it is a special case of a ramp function (a “truncated” version of a linear function): 0 for values under a certain threshold and linear function for values above the threshold.
The final output of the neuron, i.e. linear combination + activation function, is used in getting a prediction or a decision. In a neural network, learning occurs when weights are adjusted to make the network produce correct outputs, quite similarly to classical linear regression.
The top layers in an artificial network need to be taught to the task using e.g backpropagation or the neural weights. Backpropagation is a technique, where in neural network fitting the gradient of a loss-function is computed using the chain rule (a mathematical formula to calculate the derivative of a composite function) with respect to the weights of the network for a single input-output example, one layer at a time.
The computation in back propagation is done backwards (like its name suggests) from the last layer in order to avoid redundant calculations in the chain rule. This makes back propagation more effective than naive direct computation of gradients.
When the neural network has learned and adapted and is deemed good enough by the person responsible for training it, it can be used for predictions.
The strength of the neural network is definitely the capacity to process and as well as the capability to be built in complex manners where they can take into account many different factors. This makes them good for automating price optimization if there are vast amounts of suitable data available. However, this is usually not the case and reinforcement learning can be more suitable to use in price optimization.
Want to read more about how AI will transform pricing?
Machine learning vs Reinforcement learning
Reinforcement learning is an area of machine learning where the machine learning models are continuously trained by making decisions in an environment and learning from the result. In reinforcement learning, the software agent adapts to make decisions often in uncertain environments and often faces a game-like scenario, where the outcome of a decision needs to be predicted in order for the “correct” decision to be made.
Reinforcement learning differs from supervised learning in that it does not require the labeling of inputs and outputs, nor does its suboptimal actions need to be corrected by the programmer or data scientist.
Rather, the model corrects these itself by adjusting the probability of trying the suboptimal action in the future according to the reward it receives from the action taken. In this sense, reinforcement learning reminds you a bit of the teaching technique where one is allowed to make a mistake in order to learn for the future instead of the teacher stepping in and correcting the situation immediately when the mistake is made.
The focus of reinforcement learning
The focus here lies in finding the balance between exploration (i.e. uncharted territory of the environment state) and exploitation (choosing the option which is thought to be optimal at the moment).
Reinforcement learning suits well for tasks that revolve around long-term vs. short term reward trade-offs, since the computer is able to make predictions for the near and far future based on what it has learnt.
The overall goal is to make the software agent to act as optimally as possible in the environment, minimizing regret (i.e. the difference in the performance of a trained software agent against an optimal agent) and maximizing the cumulative reward.
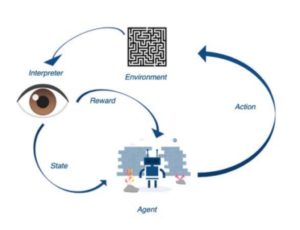
In reinforcement learning, we can use a couple of different methods making it a powerful tool in certain use cases. Samples are used to optimize performance, whereas function approximation is used to deal with large environments. This means that reinforcement learning can be very useful when we are dealing with a large environment with the following conditions.
- Analytical solutions for the environment are not available and only a model of the environment is
known - Only a simulation model of the environment is given
- Interacting with the environment is the only way to collect information about it
The conditions above perfectly illustrate why reinforcement learning is the ideal form of AI for price optimization. We often have (or at least have the possibility to gather) a lot of data and the environment (in this case, the market for the product or service) is large, but no clear theory of why certain things happen e.g. why a product sells better at a slightly lower price than a more reduced price.
In pricing, the best way to collect data is also to interact with the environment, in this case by adjusting prices, and learning from it. Furthermore, the market of products or services is often not static and can change over time as the environment changes (e.g. new technologies are developed and consumers adapt to these, changing their consumption preferences), which means that reinforcement learning allows the software agents to adjust their behavior accordingly with the changed environment.
Now that we’ve covered the basics of why reinforcement learning is optimal when you want to optimize prices, it’s time to dig a little deeper into the technical aspects of how reinforcement learning works.
The environment for reinforcement learning is typically stated in the form of a Markov decision process (MDP). The process starts with the software agent taking an action in an environment. This action is interpreted into a reward and a representation of the state of the environment. These are then fed back to the software agent. When the result is fed back, it allows for learning for the future as the agent becomes “aware” of the result of the decision it made. To support the explanation above, we can take a look at the following technical explanation of the process:
(courtesy of: Wikipedia)
- A reinforcement learning agent interacts with its environment in discrete time steps.
- At each time the agent receives an observation ot, which typically includes the reward rt.
- The agent then chooses an action at from the set of available actions. This action is subsequently
sent to the environment. The environment moves to a new state st+1 and the reward rt+1 associated with the transition (st, at, st+1) is determined. - The goal of a reinforcement learning agent is to collect as much reward as possible.
- The agent can choose any action as a function of the history, possibly randomly.
- When the agent’s performance is compared to that of an agent that acts optimally, the difference
in performance gives rise to the notion of regret. - In order to act near optimally, the agent must reason about the long term consequences of its
actions (i.e., maximize future income), although the immediate reward associated with this might
be negative.
Implications on price and profit optimization
Now you are probably asking yourself; “how does this apply to price optimization?” Well, it’s really quite straightforward:
- The environment is the current market where the product is being sold
- Actions are changes in price made by the AI process
- Changes in the environment’s state are the volumes sold when the price is a certain amount.
- Reward is the amount of profit received by the AI process from the price change it made
- If the environment changes due to external factors such as the COVID-19 pandemic, when the agent is performing an action, the change in the environment state and reward received can be different than previously in a situation and the agent learns from this, adjusting its behavior accordingly.
FAQ
How does machine learning specifically aid in addressing the challenges of pricing and profit optimization in dynamic market environments, such as those influenced by the COVID-19 pandemic, compared to traditional rule-based approaches?
- By processing vast amounts of data in real-time, machine learning algorithms can detect patterns and trends that humans may overlook. This allows businesses to react rapidly to changes in market demand, such as those seen during the COVID-19 pandemic, by adjusting pricing strategies accordingly. Unlike rule-based approaches, which rely on predetermined guidelines, machine learning algorithms continuously learn from new data and adapt their pricing strategies to optimize profits in evolving market conditions.
- By processing vast amounts of data in real-time, machine learning algorithms can detect patterns and trends that humans may overlook. This allows businesses to react rapidly to changes in market demand, such as those seen during the COVID-19 pandemic, by adjusting pricing strategies accordingly. Unlike rule-based approaches, which rely on predetermined guidelines, machine learning algorithms continuously learn from new data and adapt their pricing strategies to optimize profits in evolving market conditions.
- While the blog post discusses the technical aspects and advantages of using neural networks and reinforcement learning in price optimization, what potential limitations or challenges might arise when implementing these advanced AI techniques in real-world pricing strategies?
- One potential challenge is the requirement for large volumes of high-quality data to train machine learning models effectively. Obtaining and managing such data sets can be resource-intensive. Additionally, the complexity of neural networks and reinforcement learning algorithms requires specialized expertise in data science and computational techniques, which may not be readily available within all organizations. That’s why the use of easy pricing software is a good solution for retailers who don’t want to spend too much time thinking about it.
Learn more about e-commerce pricing
All things e-commerce pricing & price optimization right in your inbox. No spam.